
En 2009, Linkedin s’est trouvé face à ce choix qui était de développer leur propre système de Message Oriented Middleware connu aujourd’hui sous le nom d’Apache Kafka.
Lorsqu’une entreprise développe un produit, elle est amenée à faire des choix techniques qui vont être lourds de conséquences, à la fois financières et humaines. Linkedin en 2009 s’est trouvé face à ce choix qui était de développer leur propre système de Message Oriented Middleware connu aujourd’hui sous le nom d’Apache Kafka.
Pourquoi Linkedin a-t-il créé Apache Kafka ?
À sa création, Linkedin a démarré comme toutes les apps devraient démarrer, avec un Monolith baptisé « Leo ». Avec les années et la croissance de Linkedin, Leo a grandi en responsabilité et en complexité. Ses instances ont été répliquées pour répondre au flux de trafic mais cela n’empêchait pas les instances en production de tomber. L’ajout de fonctionnalité, le débuggage et la maintenance devenaient de plus en plus compliqués. Or il était crucial pour Linkedin d’assurer un taux de disponibilité maximum, comme le faisait Facebook.
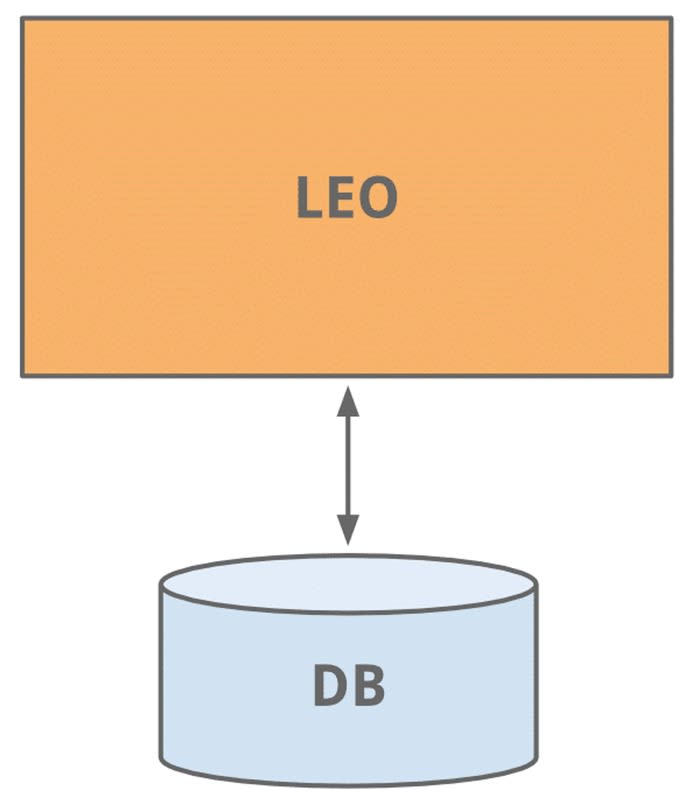
En 2009, Linkedin comptait déjà 37 millions d’utilisateurs et avait déjà bien entamé sa transition du Monolith Leo à une architecture orienté services. Or le fort couplage qui existait entre les différents modules de Linkedin rendait difficile la gestion du flux d’information. Entre les logs, le contenu généré par les utilisateurs, les profils, les connexions, les clusters de recherches, il devenait impossible de suivre le flux de données à cette échelle.
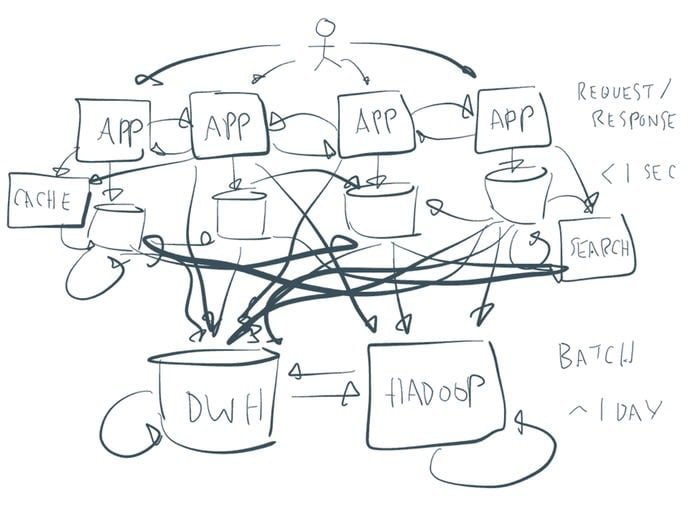
LinkedIn a initialement créé une multitude de pipelines pour émettre et traiter leurs flux de données suivant les services qui en sont à l’origine ou destinataires. Étant donné le nombre croissant de pipelines à maintenir, Linkedin a fait le choix de développer son propre middleware de messagerie, qu’on connaît aujourd’hui sous le nom d’Apache Kafka.
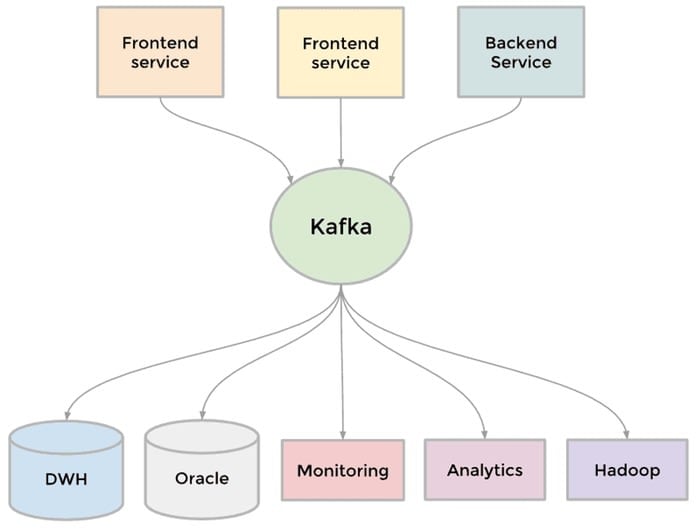
Apache Kafka gère aujourd’hui plus de 500 milliards d’événements par jour chez Linkedin.
À quoi sert Apache Kafka ?
Dans le reste du monde, peu d’applications ont des problématiques de la taille de ceux de Linkedin, alors en quoi Apache Kafka peut être utile au commun des mortels ?
Apache Kafka est un système de messagerie distribué (appelé aussi Message Oriented Middleware) permettant à des services ayant besoin de données de s’inscrire à un ou plusieurs autres services producteurs de données.
Ordonnancement des messages
Dans certains cas d’usage, pouvoir traiter la donnée dans l’ordre est essentiel. Apache Kafka conserve l’ordre des données qui lui sont communiquées et garanti, par partition, l’ordre de production des messages livrés aux consommateurs.
Conçu pour la vitesse
Sans avoir besoin de beaucoup de ressources hardware, Kafka est capable de traiter une grande quantité de donnée à grande vitesse. Sa scalabilité est facile à mettre en place en augmentant le nombre de clusters, de producers ou de consumers.
Persistance des données
Apache Kafka garde en mémoire les messages pendant une durée déterminée. Contrairement à d’autres Message bus qui détruisent les messages à l’instant où ils sont consommés, cette persistance permet de rejouer les messages s’il y avait un souci au niveau du traitement.
Stabilité
La gestion du Kafka cluster est automatique, le rendant très stable et tolérant aux problèmes machine. Grâce à Zookeeper, Kafka sait automatiquement router les messages vers les bons Kafka broker, même en cas de défaillance de l’un d’entre eux.
Comment fonctionne Kafka ?
Topics et Partitions
Dans Kafka, les données sont rangées par Topic. Ils correspondent à une table SQL ou une collection MongoDB. Ils représentent le flux de donnée et sont identifiés par leurs noms. Vous pouvez créer autant de topics que vous souhaitez.
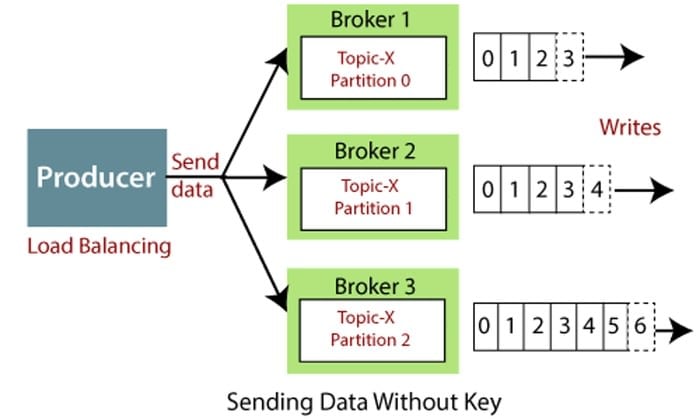
Les topics sont divisés en partitions. Là encore, suivant vos besoins vous pouvez avoir plus ou moins de partitions. Kafka va récupérer les messages produits et automatiquement les répartir à travers les différentes partitions du topic. Chaque message créé aura un ID incrémenté par partition.
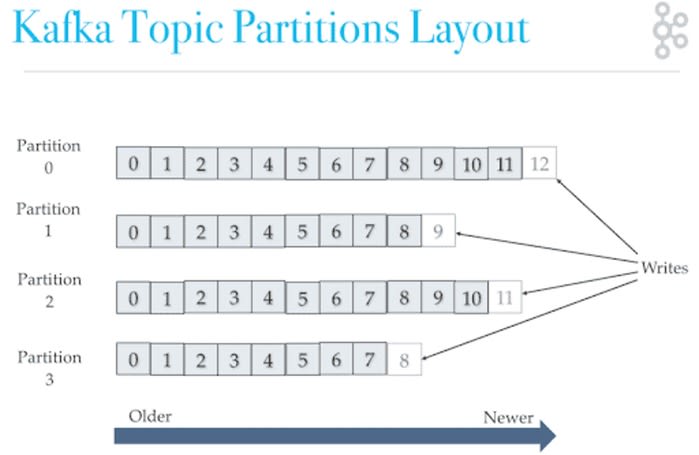
Attention, l’ordre des messages est garanti pour chaque partition et non pas à travers les partitions. Par exemple, Kafka garanti que le message 1 de la partition 1 a été produit avant le message 2 de la partition 1 mais ne peut pas savoir sans lire le message s’il a été produit avant le message 2 de la partition 3.
Les messages empilés dans les partitions sont stockés pour une durée limitée dans le temps (7 jours par défaut). Cela permettra aux consumers de pouvoir relire tous les messages qui sont toujours dans la pile si besoin.
Kafka Brokers
Pour être un système distribué, Kafka fonctionne sous forme de cluster hébergeant plusieurs Kafka brokers. Chaque Kafka broker correspond à un serveur, identifié par un ID, et contient des partitions des topics (pas plus d’une partition par topic par Kafka broker). Kafka va automatiquement attribuer les partitions dans les brokers disponibles.
Producer
Les producers sont en charge de créer la donnée dans un topic et l’envoyer. Ils vont automatiquement distribuer les messages à travers les différentes partitions disponibles.
Consumer
Les consumers sont en charge de lire les messages contenus dans un topic. Ils savent automatiquement lire les messages de différentes partitions du topic et la donnée est lue dans l’ordre suivant chaque partition.
Pourquoi est-il si populaire
Simplicité
Kafka a gagné en popularité grâce à sa simplicité. Une fois qu’on a compris ses principes et son fonctionnement, vous pouvez brancher tous vos flux de données à Kafka pour les coordonner.
De plus en plus de services cloud proposent des instances Kafka managés comme confluent ou Aiven.
Performance
Sa capacité à déplacer un grand volume de donnée a trouvé preneur dans le monde de l’entreprise. À une période où de plus en plus de données sont créées à chaque instant et l’appétit insatiable des entreprises de tout stocker pour des futurs besoins de datasets à des fins de Machine Learning par exemple, Kafka répond à ce besoin.
En savoir plus
Voici une vidéo de Stéphane Maarek, créateur de Conduktor, un client graphique pour Kafka, qui a tout une chaîne YouTube au sujet de Kafka:




