
Dans les articles précédents, nous avons vu comment créer une Node JS API et comment y connecter une base de données MongoDB. Aujourd’hui, nous allons voir comment implémenter une architecture 3 tiers ou n-tiers à notre API Node JS.
Jusqu’à maintenant, nous avons ajouté le code de notre API dans un seul fichier. Aujourd’hui nous allons revoir l’architecture de notre API avant que le code source ne devienne un énorme plat de spaghetti 🍝.
Qu’est-ce que l’architecture 3 tiers ?
L’architecture 3-tiers est un pattern d’architecture de code source qui permet de séparer les différentes couches de l’application. À l’instar du pattern MVC, l’architecture 3 tiers propose de séparer la couche donnée, la couche métier et la couche interface utilisateur.
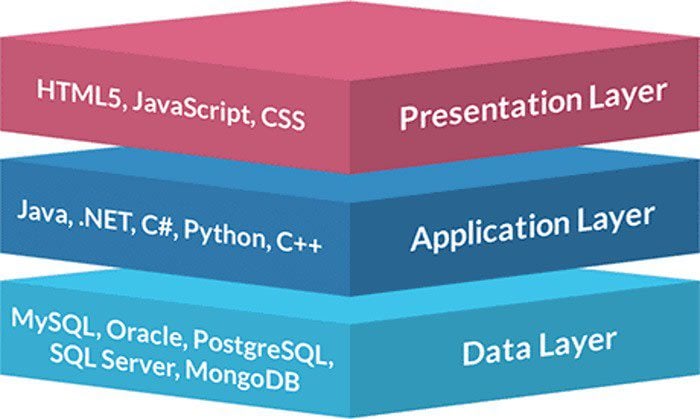
ℹ️ Dans le cas d’une API, la couche d’interface est simplement le retour JSON et non pas des fichiers HTML.
Comment fonctionne l’architecture 3-tiers ?
Avant de réinventer la roue, je trouve pertinent d’observer comment les frameworks dominants du marché ont fait leurs choix d’architecture. Le travail réalisé est issu d’années d’expérience de la part des contributeurs des projets open source et il serait dommage de se priver de ce savoir.
Que ce soit NestJS, Adonis, Laravel ou Ruby on Rails, tous ces frameworks ont choisi une architecture MVC du fait qu’ils sont principalement utilisés pour créer une application ou un site en Server Side Rendering. Lorsqu’on conçoit une API, nous n’avons pas de notions d’interface mais l’architecture va rester sensiblement la même.
Les Models – la couche data
Dans l’architecture 3-tiers, comme en MVC, la couche donnée réside dans ses propres modules.
Le but est de découpler la logique métier des opérations de base de données. Ainsi, vous pourrez faire évoluer votre métier et votre base de données séparément. Par exemple, si vous devez faire évoluer une fonctionnalité et que votre code métier se reflète que par des requêtes SQL ou des requêtes Mongo, le travail du développeur va être beaucoup plus délicat et vous serez dans l’incapacité de faire des tests unitaires sur votre fonction.
Les Controllers et les Services – la couche applicative
Dans l’architecture 3-tiers, une seule brique représente la couche applicative. Or cette brique peut être scindée en plusieurs niveaux. On parle là d’une architecture N-Tiers.
Dans une application très simple, mettre son code métier dans le controller peut être acceptable. En revanche dès que votre application se complexifie, il est considéré comme meilleur pratique de séparer votre logique métier en Services ou Repositories et ne laisser au controller que les tâches de validation, vérification de droits utilisateurs etc.
À vous d’implémenter votre architecture 3-tiers
À toi de jouer ! Nous allons retravailler l’architecture de notre application en séparent plusieurs briques dans des modules séparés.
Etape 1 – Séparer la connexion à la base de données
Cette étape étant délicate, je vais te guider un peu plus que pour les autres.
Jusqu’à maintenant, votre serveur et votre base de données étaient lancés tous les deux depuis le fichier index.js. Ce qu’on va faire c’est séparer la connexion à la base de données dans un autre fichier.
Créez un fichier database.js à la racine du projet:
const database = {}database.connect = async () => { /** * Import MongoClient & connexion à la DB */ const MongoClient = require('mongodb').MongoClient; const url = 'mongodb://localhost:27017'; const dbName = 'parkingApi'; let db MongoClient.connect(url, function(err, client) { console.log("Connected successfully to MongoDB Server"); db = client.db(dbName); database.db = db });}module.exports = databaseDans ce fichier, je commence par créer un objet vide que je vais appeler database. Cet objet englobera une méthode que j’appelle connect et que je déclare juste après. Tu remarqueras que j’ai récupéré le code présent dans index.js.
Dans la callback de la connexion, j’ai créé la clé db à laquelle j’ai attribué la connexion à la base de données 'parkingApi'.
Dans le tuto précédent, j’utilisais l’objet db pour faire mes requêtes à la base de données, par exemple:
db.collection('parkings').find({}).toArray()Étant donné que je vais avoir besoin d’utiliser cet objet pour faire des requêtes dans d’autres fichiers que database.js, je l’ajoute à l’objet database que je vais exporter.
Ainsi je pourrais réutiliser ma connexion à la base de données dans d’autres fichiers.
Pour créer cette connexion au lancement du serveur, je modifie le fichier index.js, j’importe le fichier database.js et je remplace tout le bloc contenant MongoClient par database.connectDB()
const database = require('./database')database.connect()Etape 2 – Extraire la couche Data
Maintenant que nous avons préparer notre app, nous pouvons mettre en place le découpage en couches séparées en commençant par la couche Data.
Créez un répertoire Model ainsi que les fichiers Parking.js et Reservation.js. Chacun de ces fichier va rassembler les opérations MongoDB.
De la même façon que nous avons procédé pour database.js, nous allons créer un objet en début de fichier qui contiendra l’ensemble des méthodes afin d’être exporté comme module.
Voici un exemple avec une requête Mongo:
const connection = require('../database')const parking = {}parking.list = async function () { return await connection.db.collection('parkings').find({}).toArray()}module.exports = parkingA votre tour de terminer le fichier en y ajoutant les autres méthodes de CRUD
Etape 3 – Séparer la couche logique
La deuxième étape de ce projet est de séparer la logique métier de nos routes.
Créez un répertoire Controller dans lequel vous créerez les fichiers parkingController.js et reservationController.js.
Pour chaque controller, nous allons créer les méthodes CRUD et faire appel aux méthodes que nous avons créé dans le module Model
const parking = require('../Model/parking')const parkingController = {}parkingController.getParkings = async (req,res)=> { try { const docs = await parking.list() res.status(200).json(docs) } catch (err) { console.log(err) throw err }}module.exports = parkingControllerOn distingue maintenant deux couches, la couche Data dans le répertoire Model et la couche applicative dans les controllers.
Complétez les fichiers pour retrouver l’ensemble des fonctionnalités de parking et réservations.
Etape 4 – Extraire les routes dans un module dédié
Jusque-là nous avons laissé nos routes les unes à la suite des autres dans le fichier index.js. Bien que pour l’instant ça soit encore tenable, chaque ajout de fonctionnalité va agrandir ce fichier qui sert pour l’instant de fourre-tout.
D’après la documentation d’express, nous pouvons extraire les routes dans leur propre module et les importer dans notre fichier index.js
Donc on va passer d’un bloc de code qui fait tout:
app.get('/parkings', async (req,res) => { try { const docs = await db.collection('parkings').find({}).toArray() res.status(200).json(docs) } catch (err) { console.log(err) throw err }})ainsi que l’ensemble des autres routes à :
app.get('/parkings', parkingController.getParkings)et index.js réduit à une seule ligne:
app.use(routes.js)ℹ️ La méthode use() de l’instance d’Express permet d’implémenter un Middleware. Le Middleware est une méthode par laquelle la requête HTTP va passer. Il peut soit l’intercepter pour en faire quelque chose de particulier, puis le passer au middleware suivant, soit l’intercepter pour traiter la requête complètement et renvoyer la réponse.
Créez un fichier routes.js à la racine du projet puis déplacez-y l’ensemble de nos routes. N’oubliez pas d’exporter le module routeur comme illustré sur la documentation.
À vous de jouer pour compléter votre refactor
Pour conclure
Vous l’avez probablement remarqué, notre architecture 3-tiers est incomplète. Nous avons toujours la couche de présentation et la couche applicative qui sont encore très liées dans le controller.
C’est un choix que j’ai décidé de garder pour ne pas ajouter de complexité prématurée à notre code. Dans les tutos suivant, nous allons ajouter de plus en plus de fonctionnalités et à ce moment-là nous séparerons la couche applicative dans des Services plutôt que de la laisser dans les Controllers
🧑🎓 Tu souhaites apprendre à développer avec NodeJS ? Inscris-toi au cours en ligne NodeJS Practical Programming pour seulement 19€ 🎓



