
MongoDB est la solution de bases de données NoSQL la plus populaire. Ne vous y détrompez pas, le SQL domine toujours les projets en production mais l’intérêt que suscite MongoDB est croissant depuis de nombreuses années.
Que ce soit par effet de mode ou pour une réelle solution technique à une problématique pour une application web, MongoDB compte aujourd’hui de nombreux gros clients et ambassadeurs.
Dans ce guide, nous allons voir tout ce qu’il y a à connaître sur cette technologie de base de données, le besoin auquel elle répond ainsi que des conseils sur le fonctionnement et l’utilisation de MongoDB pour vos projets.
L’origine de MongoDB
MongoDB a mis en service la version 5.0 de sa base de données NoSQL. Dans cet article, découvrez les nouveautés qu’apporte cette release ainsi que leurs explications.
Le projet initial
C’est en Automne 2007 que Kevin Ryan, Dwight Merriman et Eliot Horowitz, entrepreneurs à succès fondent la société 10gen, avec pour but de proposer un produit Plateform as a Service, similaire à Heroku, AWS Elastic Beanstalk ou Google App Engine, mais basé sur des composants opensource.
Leur expérience à travers différents projets web tel que DoubleClick et ShopWiki leur ont appris qu’une application qui devient populaire va se heurter à des problèmes de scalabilité au niveau de la base de données. Dans leur recherche d’une base de données à intégrer dans leur produit PaaS, aucune solution open source répondait à leurs besoins de scalabilité et de compatibilité avec une architecture cloud.
C’est pourquoi, l’équipe de 10gen a développé en interne une nouvelle technologie de base de données NoSQL, orientée documents. Ils la baptiseront MongoDB, inspiré du mot « Humongous » qu’on pourrait traduire par « Gigantesque », à l’instar des données qu’elle est censée héberger.
La naissance de MongoDB
Le produit PaaS développé par 10gen, baptisé ed, ne trouvant pas vraiment preneur, les fondateurs ont décidé d’en extraire la technologie de base de données. En Février 2009, MongoDB est mis en open source et le nombre d’utilisateurs a cru de manière exponentielle au sein du Google group rassemblant la communauté d’early adopters.
Au 1er Mars 2009, seulement 9 threads existaient sur ce groupe. Trois mois plus tard ce nombre s’élevait à 613 !
MongoDB a été conçu pour la vitesse. Les données reposent sur des documents BSON, diminutif de binary JSON. Le BSON permet à MongoDB d’être d’autant plus rapide dans le calcul pour rechercher des données dans les documents.
Afin d’être encore plus performant dans ses requêtes, MongoDB invite à la dénormalisation de la donnée dans ses documents. Là où une bonne pratique en SQL était d’avoir des tables spécifiques et clés étrangères pour faire référence à une donnée lors de jointures, MongoDB encourage à dénormaliser en dupliquant la donnée là où elle est demandée.
Bien que MongoDB propose des mécanismes de références, il faudra les utiliser à bon escient afin de bénéficier des performances qu’apporte une base de données MongoDB.
MongoDB a été conçu à l’ère du cloud et de l’infrastructure distribuée. Pour assurer la stabilité, un des concepts clé de MongoDB est d’avoir en permanence plus d’une copie de la base de données disponible dans le but d’assurer une disponibilité toujours aussi rapide même en cas de défaillance de la machine principale. Cette capacité à répliquer la base de données sur plusieurs machines dans plusieurs endroits facilement permet d’améliorer la scalabilité horizontale d’une base de données.
MongoDB a été conçu pour la flexibilité. Contrairement aux bases de données SQL, les données d’une collection Mongo peuvent être complètement hétérogènes. C’est ce qu’on appelle le Schemaless. L’avantage de ne pas forcément avoir de structure stricte de la donnée est de pouvoir faire évoluer rapidement sa structure de donnée.
Cette flexibilité est très appréciée à tous les stades de maturité d’une application. Là où en début de projet, la modification d’un schéma de données en SQL se fait relativement facilement, cette même modification peut devenir un enfer dans un projet comportant plusieurs centaines de tables reliées. Les migrations complexes en SQL demandent aux administrateurs de bases de données de mettre le système en Standby, ce que détestent faire les applications générant du chiffre d’affaires.
C’est à cette problématique que répond MongoDB avec la liberté de pouvoir ajuster les propriétés de chaque document dans une collection, sans nécessiter de modifier tous les documents de la collection.
Toutefois, le Schemaless a ses inconvénients. Il devient plus difficile de faire des opérations d’analyse sur la donnée si tous les documents ne suivent pas la même structure. C’est pourquoi il est également possible d’imposer un Schema à la collection.
Qu’est-ce que MongoDB en 2020
Les produits MongoDB
MongoDB
Le cœur de métier de MongoDB est sa technologie de base de données NoSQL orientée documents. Elle est aujourd’hui utilisée dans plus de 100 millions de projets.
MongoDB Atlas
MongoDB Atlas est la solution cloud de Database as a Service (DBaaS). Atlas vous déploie un serveur MongoDB managé sur un cloud Amazon Web Services, Google Cloud Platform ou Microsoft Azure, dans la région de votre choix. Vous aurez le choix de la taille de votre cluster tout en ayant l’avantage d’avoir votre base de données managée par l’équipe d’ingénieurs de MongoDB.
MongoDB Atlas permet de déployer un serveur MongoDB dans une infrastructure cloud chez AWS, GCP ou Azure.
Atlas propose même un plan gratuit pour 500MB, idéal pour vos projets perso ou pour expérimenter.
MongoDB Compass
MongoDB Compass est le client GUI officiel développé par MongoDB. Cet outil complet va vous permettre de consulter, modifier, exécuter des requêtes ou des agrégations sur votre base de données locale ou cloud directement depuis son interface graphique. Le travail des designers Mongo offre une expérience utilisateur et une interface agréable pour manipuler vos données.
MongoDB Realm
Realm est une base de données allégée embarquée sur le client mobile. Dans le cas d’une application mobile, Realm vous permet de stocker une partie de la donnée directement sur l’appareil et de coordonner des synchronisations avec la base de données principale suivant différents événements. C’est idéal pour éviter des requêtes réseau et permettre une meilleure utilisation hors ligne de l’application.
MongoDB Charts
Charts est le moyen de créer des graphiques pour visualiser votre donnée directement depuis MongoDB. Vous pourrez créer plusieurs types de graphiques en vous basant sur la donnée que vous avez sur votre cluster Atlas et les intégrer directement sur votre site directement en HTML. Charts permet d’exploiter vos données rapidement sans avoir à développer une interface Frontend spécifique pour ce besoin.
Charts est le moyen de créer des graphiques pour visualiser votre donnée directement depuis MongoDB
MongoDB Charts apporte toute sa valeur dans sa capacité à analyser des données fraîches. En effet, ses visualisation peuvent s’actualiser chaque 60 secondes et puise la donnée directement dans le cluster où sont entreposées les données produites par votre application, ce qui n’est pas le cas des systèmes de BI traditionnels qui nécéssitent aux application d’extraire leurs données vers un data warehouse afin de procéder aux requêtes d’analytics.
Cloud Manager
Cloud Manager est un outil complet de monitoring et d’optimisation de performance pour un cluster sur MongoDB Entreprise Advanced. Vous avez accès à une douzaine d’indicateurs à travers votre base de données afin d’analyser les performances de comprendre les requêtes effectuées par votre application. Un système d’alerte peut être configuré pour vous prévenir d’urgences et se connecte nativement sur Slack, DataDog ou PagerDuty.
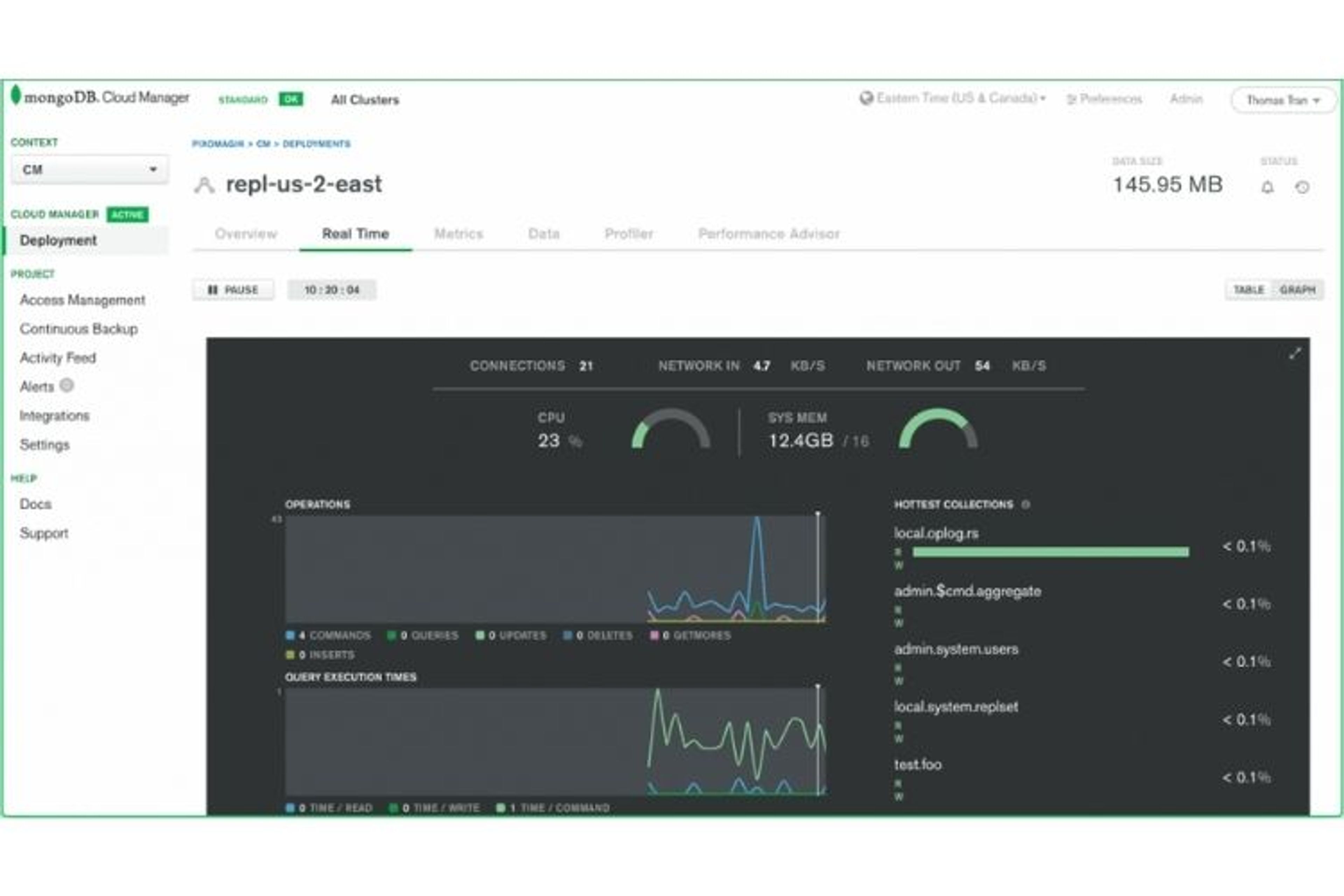
MongoDB cloud manager permet d’analyser les performances du cluster et d’optimiser les requêtes.
Cloud Manager est également capable d’identifier les requêtes lentes et suggérer des index à ajouter afin d’améliorer les performances de votre base de données.
Atlas Search
Atlas search est un des nouveaux nés de la famille Mongo Cloud. Il a pour but de concurrencer Algolia et ElasticSearch sur le terrain des moteurs de recherche. Il permet d’indexer sa donnée différemment afin de pouvoir avoir une fonction de recherche plus fine et plus intelligente qu’une simple requête avec filtres.
La communauté MongoDB
Très présente depuis les premiers instants de MongoDB, la communauté vit maintenant sur un forum très actif. Vous y trouverez des ressources pour apprendre, poser vos questions et découvrir les bonnes pratiques.
Cette grande communauté est un atout pour s’extirper de points bloquants lors de votre développement et de trouver des solutions à des problèmes épineux grâce à l’intelligence collective.
Les atouts techniques de MongoDB
Vitesse de lecture
Duplication de la donnée
Depuis des années, la bonne pratique en SQL était la normalisation des données. Afin d’assurer la meilleure fiabilité des données, il fallait éviter la duplication et faire référence à une autre table contenant les définitions. Par exemple, dans un outil de gestion de clients, on trouverait une table adresse et une table ville. La table adresse utiliserait une clé étrangère pour faire référence à une ville plutôt que de saisir la ville dans la table adresse.
Table clients:
| id | Client | ville_id |
| 1 | François | 1 |
| 2 | Marcel | 2 |
| 3 | Guillaume | 1 |
Table ville:
| id | ville |
| 1 | Paris |
| 2 | Lille |
Ce paradigme permettait d’éviter de la duplication de donnée et permettait d’éviter les erreurs de saisie, comme par exemple une faute de frappe ou une casse différente qui rendrait l’analyse fausse. Il était aussi dû à des contraintes matérielles historiques d’une époque révolue où les infrastructures étaient on premise et le coût de stockage plus élevé qu’aujourd’hui.
MongoDB a fait le choix contraire d’encourager la duplication des données.
En effet, en SQL comme en Mongo, les requêtes les plus lentes sont celles qui impliquent des références à d’autres tables ou d’autres collections.
Aujourd’hui, le coût de stockage étant bien plus faible et l’infrastructure distribuée étant bien prise en charge par MongoDB, il y a beaucoup moins de problèmes à dupliquer la donnée.
Bien qu’il soit possible de faire référence à d’autres documents dans Mongo, il est encouragé d’écrire le maximum de donnée au sein d’un document. La limite d’un document étant de 16Mo, l’utilisation de la référence trouve son intérêt lorsqu’un document devient trop lourd pour tout inclure.
Prenons l’exemple d’un blog utilisant une base de données MongoDB. Là où nous serions tentés d’avoir une collection Posts et une collection Comments, Mongo nous encourage à inclure les commentaires dans le post. Il n’y a pas d’usages où nous aurions besoin de charger les commentaires sans les posts donc il est tout à fait possible d’imbriquer les commentaires dans le document d’un article du blog.
Cette imbrication permet à MongoDB d’améliorer ses performances de lecture en ne lisant qu’un document plutôt qu’à devoir en parcourir plusieurs et rassembler un objet pour le livrer au serveur.
Diversité des types index
Au cœur de sa vitesse de lecture réside la diversité des index proposés. L’utilisation et la combinaison de ces index permettent à vos requêtes de parcourir un échantillon de la donnée au lieu d’effectuer la recherche sur l’ensemble de la collection. MongoDB offre la possibilité d’indexer un objet sur plusieurs champs, d’indexer un champ contenant un tableau d’éléments, d’indexer des coordonnées GPS et d’indexer un bloc de texte pour pouvoir faire une recherche dans son contenu.
Comme pour toute base de données, la multiplication des index augmente la taille de la base de données et la lenteur à l’écriture. C’est pourquoi une stratégie d’index est clé pour avoir le minimum d’index possible tout en couvrant un maximum de requêtes provenant de l’application.
Performances à l’écriture
Comme on a pu le voir plus haut, un cluster de base de données MongoDB est répliqué plusieurs fois, avec une base primaire et des répliques considérées comme secondaires. MongoDB peut présenter des performances intéressantes même à l’écriture grâce à la notion de Write concerns. Plus une base est répliquée et/ou shardée (la notion de sharding est expliquée ci-dessous), plus MongoDB doit aller écrire la donnée à différents endroits.
Le write concern est la notion de confirmation d’écriture. Par défaut, le write concern est défini à 1, c’est-à-dire que lors d’une écriture, MongoDB va écrire la donnée une première fois sur la base de données primaire et vous retourner sa confirmation. Elle se chargera derrière les rideaux de coordonner les réplications.
Suivant vos besoins, vous pourriez augmenter le write concern si vous voulez vous assurer que la donnée a été répliquée sur les bases de données secondaires de votre cluster, ou au contraire le réduire à zéro pour désactiver cet accusé d’écriture en base et augmenter d’autant plus la performance.
Haute Disponibilité
En informatique comme dans la vie, la seule certitude est que quelque chose va mourir.
Partant de ce constat et du positionnement Cloud first, MongoDB fait le choix de répliquer votre base de données en plusieurs serveurs mongod. Un primaire et plusieurs répliques.
Si votre machine (virtuelle) hébergeant le serveur MongoDB venait à être défectueuse, votre donnée reste très rapidement accessible grâce aux répliques followers disponibles. La VM défectueuse serait supprimée et un nouveau Leader émergerait pendant qu’un nouveau follower serait en cours de création.
Côté application, votre driver MongoDB va être en mesure d’attendre la réponse à sa première tentative d’écriture, puis de la retenter s’il le faut pour s’assurer que les opérations d’ajout ou de modification de données sont bien prises en compte.
Cette réplication permet à votre base de données d’être en permanence disponible.
Scalabilité
La méthode la plus facile de scaler une base de données est le scaling vertical, qui consiste à rendre la machine hébergeant la base de données plus puissante en ajoutant de la RAM, de l’espace disque et de la puissance CPU. Cette méthode est vite coûteuse car plus les composants sont puissants ou avec une grosse capacité, plus ils sont chers.
L’autre méthode consiste à scaler horizontalement, en ajoutant plus de machines pour héberger la même base de données. Cette méthode est plus compliquée car jusque-là les bases SQL perdaient en performances lors de requêtes qui impliquaient plusieurs machines.
MongoDB propose la notion de Sharding. Cette méthode permet de distribuer la data à travers plusieurs machines afin d’optimiser les performances des requêtes entrantes. La donnée va être répartie à travers différents fragments de la base de données et en utilisant un Shard Key, les requêtes mongo vont être très efficaces pour aller récupérer de la donnée directement dans le fragment qui la contient.
Flexibilité
Contrairement aux bases SQL, une base MongoDB n’a pas forcément besoin d’avoir une structure de donnée fixe pour l’ensemble des objets présents dans une collection.
En effet, en SQL si vous souhaitez ajouter une colonne à votre table Clients, il faudra faire une migration pour ajouter une colonne et cette propriété sera NULL pour tous les clients n’ayant pas ce champ renseigné.
Avec MongoDB, vous pouvez faire du Schemaless. Un client pourra avoir le champ « FAX » parce qu’il est un des derniers spécimens sur terre à posséder une telle machine sans pour autant que tous les clients aient à avoir cette propriété.
Le fait de proposer du Schemaless permet un changement rapide.
Ça paraît essentiel mais toute application a besoin d’itérer sur ses fonctionnalités afin d’innover. Ce changement est facile au début, quelle que soit la technologie de base de données choisie.
En revanche, les migrations SQL peuvent être longues, et nécessiter du temps d’indisponibilité de l’application, ce qui est coûteux pour une entreprise qui risque de perdre des clients.
Les fonctionnalités incontournables
Les agrégations
Le but de toute base de données est de stocker et ordonner de la donnée en vue de pouvoir l’exploiter. Pour pouvoir exploiter ces données, MongoDB propose des opérateurs d’agrégations.
Les agrégations sont des séries d’opérations de manipulation sur une donnée en vue de produire un document spécifique. Elles permettent d’extraire certaines données d’objets, de les grouper, de les assembler dans un nouveau format afin de pouvoir récupérer la donnée structurée comme on le souhaite.
La recherche textuelle
L’index Text de MongoDB permet aux utilisateurs de rechercher spécifiquement du texte à l’intérieur d’un objet. Par exemple pour rechercher un mot-clé dans une série d’articles de blog ou un mot spécifique dans une fiche article pour un site e-commerce.
Les coordonnées GPS
MongoDB propose également des index Géospatiaux qui permettent de définir un point via des coordonnées GPS, ou une aire, à partir d’un point central et d’un rayon ou bien à partir de plusieurs points afin de définir une zone spécifique.
Cette fonctionnalité est utile pour stocker des lieux et calculer la distance entre plusieurs points.
Les transactions
MongoDB garde la réputation qu’il n’est pas possible de faire une opération de transaction et qu’il faut privilégier une base SQL dans le cas où c’est une fonctionnalité essentielle à votre application.
Qu’est-ce qu’une transaction?
Lorsqu’un geste métier dans une application nécessite que plusieurs opérations en base de données se déroulent pour être considérées comme complète, il s’agit d’une transaction.
Par exemple, lorsqu’un virement bancaire a lieu, il faut absolument que l’argent sur le compte A soit déduit ET qu’il soit crédité sur le compte B. Si l’opération d’écriture échouait en plein milieu, le compte A se retrouverait débité, le compte B ne serait pas crédité et le montant transféré serait perdu dans la nature. Lors d’une transaction, si l’opération n’est pas complètement terminée, la base de données effectue un Rollback avant de signaler l’erreur.
MongoDB n’a pas toujours su faire les transactions.
Souvenez-vous, MongoDB est conçu pour être distribué sur plusieurs machines. Dans l’exemple de la transaction bancaire, on peut imaginer que les comptes se situent sur différentes machines, dans différentes régions du monde. Il est donc d’autant plus compliqué de faire ce genre d’opérations et de garantir son atomicité.
MongoDB a introduit les transactions à travers les collections shardées avec la version 4.2.
Il est maintenant possible d’effectuer des transactions sur plusieurs documents, même si la collection est shardée sur plusieurs machines.
Les limites de MongoDB
Toutes ces belles fonctionnalités de MongoDB semblent faire d’elle une techno à toute épreuve. Or dans la tech, la seule vérité est qu’il n’y a pas de « Silver bullet ». Toute fonctionnalité vient en échange d’un coût.
Voici les limites de mongoDB
La dénormalisation à outrance
Comme on l’a vu, MongoDB incite à la dénormalisation. Que ce soit dans la documentation et les ressources de formation officielle de MongoDB University, il vous est encouragé de dupliquer votre donnée dans la mesure du possible.
Bien que çà paraisse pertinent au vu des faibles coûts des capacités de stockage aujourd’hui, cette duplication va créé un nouveau problème: l’intégrité des données.
Imaginez qu’il faille mettre à jour plusieurs collections à chaque fois qu’un utilisateur va corriger son adresse. Cette complexité s’ajoute à la charge des développeurs qui, à chaque fois qu’ils vont toucher une fonctionnalité qui fait référence aux adresses, vont devoir se charger de coordonner l’update dans toutes les collections.
Ce genre de duplication va provoquer des erreurs où deux collections vont avoir des données contradictoires et il faudra créer des batch de redressement pour corriger la donnée.
Les jointures
Les jointures ont été introduites dans MongoDB avec l’agrégat $lookup depuis la version 3.2. Cette fonctionnalité vient répondre aux besoins dans les cas où la dénormalisation n’est pas une option et qu’il n’y a pas d’autre choix que de créer une référence à un autre objet.
Or mongoDB n’a pas été conçu pour ce type de besoin et les performances d’une requête avec un agrégat $lookup sont bien moins intéressantes. Vous perdez l’avantage initial que propose MongoDB.
Si votre application a besoin de mettre en relation beaucoup de données, le choix de MongoDB n’est peut-être pas le bon.
La surindexation
MongoDB plaît par ses performances. Or pour arriver à ces performances sur un maximum de requêtes, vous serez incité à créer de plus en plus d’index.
Cette surindexation va taxer les performances à l’écriture de votre base de données.
Chaque ajout d’un objet dans la collection va nécessiter une création d’une multitude d’index dans plusieurs collections, ce qui va être gourmand en ressources de votre base de données.
Vous pourriez être tentés de coupler une base MongoDB pour la lecture uniquement et avoir une base dédiée à l’écriture, telle que Cassandra, qui viendrait alimenter plus tranquillement la base de données MongoDB. Cette solution, bien que fonctionnelle, ajoute une immense complexité à votre application et est souvent le fruit d’une mauvaise utilisation de vos index.
Souvenez-vous, vous n’êtes pas Facebook, vous ne devriez pas avoir leur niveau de complexité.
Pourquoi s’intéresser à MongoDB ?
Compétence recherchée
Le succès qu’a connu MongoDB auprès des développeurs s’est également retrouvé au sein des projets d’entreprises. Aujourd’hui, on retrouve des projets utilisant MongoDB dans des Startups, des grands groupes, des projets gouvernementaux et des associations.
Parmi les utilisateurs Fraançais de MongoDB on retrouve entre autre AXA, Bouygues Telecom et Leroy Merlin. A l’heure où j’écris cette page, plus de 2000 offres d’emploi en France mentionnent MongoDB sur Linkedin.
Qui devrait apprendre à utiliser MongoDB ?
Tout développeur Backend, quelle que soit la techno utilisée aurait intérêt à se former sur les bases de MongoDB. Apprendre à créer une base de données et faire les premières requêtes CRUD est suffisant dans un premier temps si vous n’avez pas de projet pour le mettre en application.
Les développeurs Fullstack JavaScript ont également beaucoup à y gagner. Les stacks employés pour les projets JavaScript utilisent plus souvent MongoDB. C’est une compétence qui vous sera probablement plus demandée qu’un développeur PHP.
Comment démarrer avec MongoDB ?
Installer MongoDB
MongoDB est disponible sur toutes les plateformes. Vous trouverez nos guides d’installations pour les différents OS:
Premières requêtes CRUD
Démarrer avec MongoDB est très simple. Il suffit de lancer son serveur Mongo sur son poste avec la commande mongod ou via une image Docker. Ensuite il suffit de saisir la commande mongo pour accéder au Mongo Shell et effectuer ses premières requêtes MongoDB.
Insérer des données dans MongoDB
L’insertion de données dans votre base de données MongoDB se fait avec une des méthodes suivante:
- insertOne()
- insertMany()
- bulkWrite()
La méthode insertOne va simplement insérer un nouveau document sans faire attention à ce qui existe déjà dans la base.
db.posts.insert({ subject: "Blog Post 1", content: "Lorem Ipsum"})La méthode insertMany quant à elle vise à insérer plusieurs documents en une opération:
Il est important de noter que l’opération insertMany n’est pas ACID si on ne la définit pas dans une transaction. C’est-à-dire que seulement une partie des documents peuvent être insérés. Si vous avez besoin de vous assurer que l’ensemble des documents soient insérés de façon atomique, il faudra utiliser la fonctionnalité de transaction.
L’opération insertMany, par défaut, va tenter d’insérer les documents dans l’ordre dans lequel vous avez fourni les documents dans votre requête Mongo.
Dans ce cas, si la tentative d’insertion d’un document retourne une erreur, la suite des documents ne sera pas traité. En effet, sans précisions de votre part, MongoDB va supposer que l’ordre d’insertion est important et va préférer vous retourner une erreur pour que vous puissiez rejouer l’opération d’insertion.
Par contre, il se peut que l’ordre d’insertion vous importe peu. Dans ce cas, vous pouvez lui préciser dans une option comme ceci:
db.posts.insertMany([{ subject: "Blog Post 1", content: "Lorem Ipsum" },{ subject: "Blog Post 2", content: "Lorem Ipsum bis" },{ subject: "Blog Post 3", content: "Lorem Ipsum ter" },{ subject: "Blog Post 4", content: "Lorem Ipsum etc" },],{ordered: false})Ainsi, le driver va pouvoir dire au moteur de base de données mongod qu’il peut procésser à l’insertion dans l’ordre qu’il veut, donnant l’accord implicite de continuer la liste même en cas d’erreur.
Modifier des données dans MongoDB
Pour modifier un ou plusieurs document dans votre base de données MongoDB, distinguer les opérations de type update des opérations de type replace.
Les opérations d’update
Les opération d’update modifie des champs spécifiques dans un ou plusieurs documents, tout en laissant le reste du ou des documents inchangés. C’est l’équivalent d’un PATCH dans une API REST.
Les méthodes pour procéder à une opération d’update sont les suivants:
- updateOne
- findAndModify
- updateMany
updateOne et findAndModify vont prendre en premier paramètre la requête discriminante pour trouver le premier document correspondant aux critères.
En second paramètre, on retrouvera le ou les opérateurs de modifications (le type de modification à effectuer). On retrouve, entre autres, les opérateurs d’update suivants:
$set: permet de définir une nouvelle valeur à un champ spécifique$inc: permet d’incrémenter ou décrémenter une valeur numérique$rename: permet de renommer la clé d’un champ$unset: permet d’éffacer une clé et sa valeur du document$mul: pour multiplier la valeur par un nombre spécifié
Prenons par exemple ce document:
{ "_id": 1 "firstName":"John", "lastName":"Doe", "occupation": "unknown", "numberOfVisits": 1, "interests":["cars","internet","marketing"]}Si on lance l’opération d’update suivante:
Nous retrouverons notre document modifié comme ceci:
db.customers.updateOne( {lastName:"Doe"}, { $set:{"occupation":"worker"}, $inc:{"numberOfVisits": 1}, $push:{"interests":"programming"} }){ "_id": 1 "firstName":"John", "lastName":"Doe", "occupation": "worker", "numberOfVisits": 2, "interests":["cars","internet","marketing","programming"]}Par défaut, si MongoDB n’est pas capable de trouver un document à partir du premier paramètre, l’opération ne fera rien.
Il est toutefois possible de passer l’option {upsert: true} en 3e paramètre pour forcer la création d’un nouveau document si jamais MongoDB n’en trouvait aucun qui correspond aux critères recherchés.
Votre requête resemblerait à ceci:
db.customers.updateOne( {firstName:"Jane","lastName":"Doe"}, { $set:{ "occupation":"worker", "firstName":"Jane", "lastName": "Doe" }, $inc:{"numberOfVisits": 1}, $push:{"interests":"programming"} })Pour que MongoDB puisse créer le document s’il n’existait pas, il faudrait remettre dans le $set les champs qui ont servi à la recherche.
Les opérations de replace
Contrairement aux updates, les replaces vont modifier l’ensemble du document.
Si on reprend notre exemple précédent du document suivant:
{ "_id": 1 "firstName":"John", "lastName":"Doe", "occupation": "unknown", "numberOfVisits": 1, "interests":["cars","internet","marketing"]}avec une opération de replace suivante:
db.customers.updateOne( {lastName:"Doe"}, {"occupation":"worker", "numberOfVisits": 1, "interests":"programming" })On se retrouverait avec le document suivant:
{ "_id": 1 "occupation": "worker", "numberOfVisits": 1, "interests": "programming"}Dans cet exemple on perdrait la majorité des informations concernant notre client.
Si on souhaite faire une opération de replace, il faut reconstruire l’ensemble du document dans l’opération.
Organiser ses collections
Si vous aviez l’habitude de développer vos applications en utilisant des bases de données RDBMS telles que MySQL ou PostgreSQL, la façon dont les données sont modélisées dans MongoDB va vous demander de remettre en question votre façon de faire.
En SQL, la bonne pratique a longtemps été de normaliser ses données. Une table fera référence aux données dans une autre via une Foreign Key, évitant ainsi la duplication de donnée et d’éventuelles inconsistances entre différents objets de la base.
En MongoDB, cette stratégie est délaissée en dernier recours en faveur de la duplication de donnée. Suivant le volume de donnée à mettre en relation, on va opter pour différentes stratégies.
MongoDB propose d’arbitrer entre deux stratégies. La relation à un autre document, telle qu’on la connaît dans les bases RDBMS, ou embed, qui se traduirait par inclure, dans le document d’origine.
Par exemple, un article de blog avec ses commentaires mis en relation:
{ "_id":"iqdsfjaf9043ngfdslk9", "title":"MongoDB: Le guide complet pour utiliser la base de données NoSQL de référence en 2020", "body":"MongoDB est une base de données NoSQL...", "comments": ["6qd77a03faf1f8436048q8", "5db57a04faf1f8434098f7f9"]}en relation avec les commentaires stockés dans la collection correspondante:
[{ "_id": "6qd77a03faf1f8436048q8", "username": "Marc", "text": "Super article", "createdAt": "2019-10-27T11:05:39.898Z",},{ "_id": "5db57a04faf1f8434098f7f9", "username": "Jean", "text": "MongoDB n'est pas du tout adapté aux gros projets, c'est un jouet", "createdAt": "2019-10-27T11:05:40.710Z"}]Ou alors, MongoDB propose d’inclure les commentaires directement dans l’objet Post de la manière suivante:
{ "_id":"iqdsfjaf9043ngfdslk9", "title":"MongoDB: Le guide complet pour utiliser la base de données NoSQL de référence en 2020", "body":"MongoDB est une base de donnée NoSQL...", "comments": [ { "_id": "6qd77a03faf1f8436048q8", "username": "Marc", "text": "Super article", "createdAt": 2019-10-27T11:05:39.898Z }, { "_id": "5db57a04faf1f8434098f7f9", "username": "Jean", "text": "MongoDB n'est pas du tout adapté aux gros projets, c'est un jouet", "createdAt": 2019-10-27T11:05:40.710Z } ]}Suivant la nature de vos documents et le nombre de relations, une stratégie sera plus préférable qu’une autre.
Relations 1-to-1
Dans le cas d’une relation one-to-one, on privilégiera le plus souvent une stratégie d’embed à une référence. Prenons l’exemple d’un client et une commande
// L'objet client{ _id: "abc", lastName: "Martin", firstName: "Pierre", email: "[email protected]"}// L'objet commande{ _id:'def' client: { lastName: 'Martin', firstName: 'Pierre', email:'[email protected]' } currency: 'Eur' amount: 1000 created_at: 2020-07-31, updated_at: 2020-07-31}Dans ce cas, l’objet client est suffisamment petit et pertinent pour l’inclure complètement dans l’objet commande.
Admettons maintenant que notre objet client soit bien plus riche en données:
// L'objet client{ _id: "abc", lastName: "Martin", firstName: "Pierre", email: "[email protected]", dateOfBirth: 1987-05-06, jobTitle: 'Ingénieur', company: 'Société Générale', address: { number: "4ter", street: "Rue Ranelagh", postalCode: "75016", city: "Paris" }, CIN: 187057534298717, premium: true, lastVisit: 2020-07-12,}Beaucoup de ces champs ne sont pas pertinents dans le cadre d’une commande. Afin d’éviter d’alourdir inutilement notre objet Commande, on peut employer une stratégie de subset embed qui consiste à inclure dans le document commande uniquement les champs qui sont pertinents pour le traitement de celle-ci.
{ id:'def' client: { _id: 'abc', lastName: 'Martin', firstName: 'Pierre', } currency: 'Eur' amount: 1000 created_at: 2020-07-31, updated_at: 2020-07-31}Cette stratégie permet d’avoir accès à la propriété _id de Client, au cas où nous aurions besoin de faire une requête pour avoir tous les détails du client, tout en proposant directement la donnée la plus utilisée dans le document Commande.
Relations 1-to-Many
Dans la plupart des cas, la stratégie d’embed dans les relations 1-to-Many apportera la meilleure performance. Au même titre que l’exemple fourni dans une relation 1-to-1 ci-dessus, le fait d’embed la donnée de l’objet cible dans l’objet d’origine apporte des gains à la lecture.
Par exemple, un site e-commerce pourrait inclure les avis dans l’objet article
{ _id: "abc", name: "Clean Code", price: 19.99, reviews: [ {client:"Tom", rating:5, comment:"Très bon livre"}, {client:"Marc", rating:4, comment:"Exemples pertinents"}, ]}L’usage le plus commun pour un site marchand est d’afficher la page produit avec les avis clients. De ce fait, en une requête simple la page a toutes les informations nécessaires pour produire la page.
Si le frontend veut proposer une page regroupant les avis de Marc sur l’ensemble des produits, il suffirait de faire une requête d’agrégation sur les reviews contenant le client Marc dans la collection article.
En revanche, le fait d’embed l’article cible dans l’article d’origine peut poser problème si le tableau est amené à croître significativement. En effet, MongoDB ne va pas apprécier avoir un objet contenant un tableau d’une longueur de 10 000.
Prenons l’exemple d’un Post Instagram d’Ariana Grande, qui possède un des comptes avec le plus de followers.
Le post en question contient plus de 68k commentaires et inclure chaque commentaire dans l’objet Post ferait dépasser les limites de 16Mo que MongoDB impose pour chaque document.
Dans ce cas, la solution est de retourner le problème et d’inclure une référence au post dans l’objet commentaire. On passe donc à une relation 1-to-1 où on va seulement mentionner l’id du post dans le document commentaire.
{ _id:'abc' post_id:'xyz', user: 'khloekardashian', comment: 'Happy birthday beautiful ❤️❤️❤️'},{ _id:'def' post_id:'xyz', user: 'djsnake', comment: '🦋'}Dans ce cas, la référence se fait sur l’objectId du document Post et une requête d’agrégation permettrait de récupérer et formater le post et les commentaires.
Comprendre les agrégations
Parfois, l’information dont on a besoin n’est pas stockée telle quelle dans notre base de données. Vous pourriez avoir besoin d’une somme, d’une moyenne, de regrouper une partie des documents seulement.
Pour ce faire, MongoDB propose les agrégations. Il s’agit d’opérations capables de se succéder afin de manipuler la donnée et retourner un ou plusieurs documents modifiés pour correspondre au besoin que vous avez.
Imaginons une collection Commandes d’un McDonald’s:
[ { _id: abc, contenu: [ {sku: "BigMac", quantity: 1}, {sku: "Moyenne frite", quantity: 1}, {sku: "Moyen Coca Zero", quantity: 1}, {sku: "Grand Coca Cola", quantity: 1}, {sku: "Grande frite", quantity: 1}, {sku: "280", quantity: 1} ], total: 21.40 type: "drive" created_at: "2020-07-27T13:07:41.657Z" }, { _id: bcd, contenu: [ {sku: "CBO", quantity: 1}, {sku: "Moyenne potatoe", quantity: 1}, {sku: "Moyen Fanta", quantity: 1}, {sku: "Grand Coca Cola", quantity: 1}, {sku: "Grande frite", quantity: 1}, {sku: "BigMac", quantity: 1}, {sku: "Sundae Chocolat", quantity: 1} ], total 26.10 type: "drive" created_at: "2020-07-27T13:07:55.657Z" }, { _id: cde, contenu: [ {sku: "CBO", quantity: 1}, {sku: "Moyenne frite", quantity: 1}, {sku: "Moyen Sprite", quantity: 1}, {sku: "Grand Coca Cola", quantity: 1}, {sku: "Grande frite", quantity: 1}, {sku: "280", quantity: 1} ], type: "a emporter" total: 23.80 created_at: "2020-07-27T13:08:41.657Z" }, { _id: def, contenu: [ {sku: "Grand Coca Cola", quantity: 1}, {sku: "Grande frite", quantity: 1}, {sku: "280", quantity: 1} ], type: "a emporter" total: 9.70 created_at: "2020-07-27T13:09:41.657Z" }, { _id: efg, contenu: [ {sku: "Grand Coca Cola", quantity: 1}, {sku: "Grande frite", quantity: 1}, {sku: "BigMac", quantity: 1} ], type: "a emporter" total: 8.70 created_at: "2020-07-27T13:09:42.657Z" }, { _id: fgh, contenu: [ {sku: "Grand Coca Cola", quantity: 2}, {sku: "Grande frite", quantity: 2}, {sku: "BigMac", quantity: 2} ], type: "a emporter" total: 9.70 created_at: "2020-07-27T13:09:42.657Z" }]Utiliser les agrégations mongodb vous permettrait de ressortir des données telles que le nombre de Bigmac vendu par jour, le classement des produits les plus vendus sur un mois, le ticket moyen par type de commande…
Savoir indexer ses données pour améliorer les performances
Les index sont la clé du succès d’une base de données MongoDB. C’est grâce à eux qu’une requête va pouvoir fournir la donnée de manière la plus efficace possible.
Qu’est-ce qu’un index?
Prenons l’exemple d’une encyclopédie. Pour trouver la page qui parle du « système solaire » vous demanderait de parcourir l’ensemble des pages de l’encyclopédie, jusqu’à trouver la bonne. En consultant d’abord l’index, les différentes notions y sont rangées par ordre alphabétique, vous pourrez très rapidement trouver la ligne qui correspond au « système solaire » qui va vous indiquer la page où vous rendre pour retrouver tout son contenu.
Quelle que soit la base de données, un index est une copie partielle de la donnée rangée de telle sorte à ce que le moteur puisse rapidement la retrouver.
Les index dans MongoDB
En suivant une stratégie d’indexation pertinente, vous améliorerez grandement les performances de lecture de votre base de données. Plus vous avez d’index, plus votre base de données va pouvoir répondre aux différentes requêtes rapidement.
Attention toutefois à avoir une stratégie d’indexation pertinente et ne pas abuser de l’outil. En effet, ajouter un index revient à faire une copie d’un fragment de la donnée. Non seulement cet index rajoute du poids à l’ensemble de votre base de données, il ralentit également les opérations d’écritures. Si la collection User a 14 index différents, lorsque vous insérerez un nouvel utilisateur, MongoDB devra recopier 14 fragments de données, ce qui a un coût en termes de performance.
MongoDB brille par la diversité de ses index. Grâce à ses différentes options, vous pourrez catégoriser les données clés de votre base de données à travers différents types d’index. Cette diversité permet d’avoir une performance de lecture optimale tout en minimisant le coût à l’écriture.
Alternatives à MongoDB
DynamoDB est le service de base de données NoSQL made in AWS. Elle est souvent opposée à MongoDB bien qu’ils ne soient pas vraiment similaires. DynamoDB est complètement managé par AWS et il n’est pas possible de l’avoir sur son propre environnement on premise ou sur un cloud concurrent. De plus DynamoDB est plus proche d’une base clé-valeur qu’une base orientée documents. Chaque élément dans la base de données est stocké dans une table contenant un id et les tables peuvent être indexées pour effectuer des requêtes plus rapidement. Dynamo s’intègre parfaitement avec les autres produits AWS et permet de sous traiter une certaine logique à l’infrastructure. Par exemple, si vous avez besoin de réagir à la mise à jour d’un élément dans la base de données, DynamoDB vous offre cette possibilité sans que vous ayez à coder cette logique dans votre application.
RethinkDB est une base de données NoSQL orientée documents qui se positionne sur les données en temps réel. Elle pousse la donnée à votre application à chaque fois qu’un évènement se produit. RethinkDB est open source et par conséquent peut se déployer sur l’infrastructure on premise ou cloud de votre choix. C’est un excellent choix si vous avez besoin de créer une application réactive à la donnée comme un tableau de bord mais elle ne supporte pas les principes ACID et un schéma de données strict. De même, si vous effectuez beaucoup de calculs sur vos données, une base de données type colonne telle que Cassandra sera plus adaptée.
FaunaDB est une base de données transactionnelle, orientée document, spécialisée sur le Serverless. Avec Fauna, les développeurs n’ont plus à se soucier de configurer un cluster. Les données sont automatiquement répliquées sur plusieurs régions et accessibles via API. Contrairement aux autres technologies,FaunaDB est opérée exclusivement par Fauna qui choisira d’opérer ses infrastructures où elle l’entend. Particulièrement adapté aux infrastructures Serverless, FanuaDB a su se faire une place dans l’écosystème Next.JS en venant concurrencer DynamoDB et l’offre Serverless de MongoDB Atlas qui est arrivée avec la version 5.0, après que FaunaDB ait pu se faire une place.
CosmosDB est la base de données, multimodèles, proposée par Microsoft sur son service cloud Azure. Proposant plusieurs APIs permettant aux développeurs d’avoir l’impression de travailler sur du MongoDB (ou du Cassandra, entre autres), CosmosDB traduit les requêtes et la modélisation des données pour les stocker dans un format qui lui est propre. CosmosDB demande aux développeurs de choisir une taille de stockage ainsi qu’un nombre de requêtes et facturera par palier en fonction.
Comment apprendre MongoDB
L’université Mongo est une excellente ressource, en anglais, pour apprendre et manipuler MongoDB. Grâce à une série de vidéos, de quiz et d’exercice, vous apprendrez à votre rythme les différentes notions de MongoDB.
La difficulté est progressive et vous pouvez sauter les premiers modules si vous êtes déjà familiers avec les bases de MongoDB. Ils proposent également d’utiliser gratuitement MongoDB Atlas pour héberger votre base de données et fournissent les jeux de données pour vous exercer.
Conclusion
Bien que MongoDB eût été conçu pour une fin bien spécifique qui était une utilisation dans le cloud distribué, son évolution et la pratique du développement web en font une base de données multi-usages.
Aujourd’hui, à moins d’avoir une raison claire de ne pas utiliser MongoDB, c’est la technologie de base de données la plus flexible et la plus adapter pour tout projet.



