
Le tutoriel d’aujourd’hui reprend l’un de ces projets, réalisé pour une startup qui cherchait à effectuer une veille automatisée via un bot Instagram.
Cet article est le quatrième de notre série Web scraping : le guide complet avec tutoriels.
En tant que développeur spécialiste du data scraping, je suis régulièrement sollicité par des personnes ou des entreprises souhaitant automatiser certains processus. Le tutoriel d’aujourd’hui reprend l’un de ces projets, réalisé pour une startup qui cherchait à effectuer une veille automatisée via un bot Instagram.
Ce tutoriel de web scraping utilise la librairie Puppeteer pour Node.js. Le code complet est disponible au bas de l’article mais je vous invite à suivre le guide pas à pas pour comprendre chaque étape et écrire facilement vos propres scripts par la suite.
Objectif du bot de web scraping pour Instagram
Le but de ce script de web scraping Instagram est de reproduire les étapes d’un procédé habituellement effectué à la main : se connecter au compte, chercher un hashtag spécifique, collecter les posts liés à ce hashtag et des informations relatives aux utilisateurs qui les ont postés (bio, nombre d’abonnés etc.).
Lancé régulièrement, ce robot automatise et optimise totalement ce processus en fournissant à cette startup une donnée complète qu’elle n’aurait pu avoir à la main, et en un temps record.
⚠️ Il est important de noter que les web apps extrêmement populaires telles qu’Instagram sont en constante évolution avec des mises à jour fréquentes. Cela signifie qu’au moment où vous lisez ces lignes, le code final issu de ce tutoriel ne sera peut-être plus adapté au nouveau template, aux nouveaux parcours utilisateur ou aux systèmes de protection de l’app. Dans ce tutoriel, je vais tâcher de prendre en compte ce facteur important en web scraping en expliquant chaque bloc de code en détail pour vous permettre d’adapter facilement le script en fonction des futures mises à jour.
Travail préliminaire
Puppeteer se base sur le navigateur Chromium. Nous aurons donc besoin de Google Chrome ou de Chromium pour obtenir un comportement au plus proche de notre script de web scraping.
Ouvrons Google Chrome (ou Chromium) en mode navigation privée (pour éviter toute interférence causée par d’éventuelles précédentes sessions) et rendons-nous sur Instagram.com.
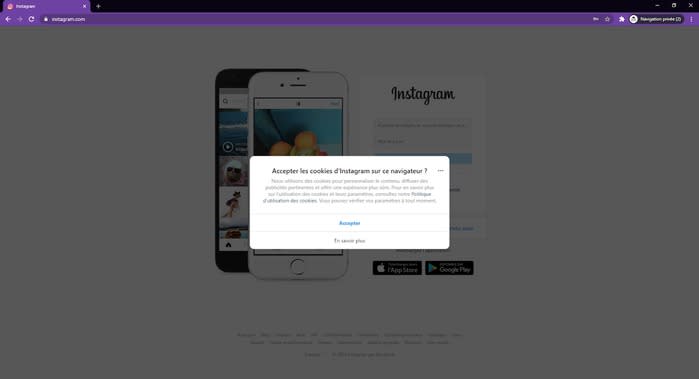
On remarque tout de suite deux interactions importantes :
- Une modale d’information à propos des cookies s’ouvre et doit être fermée en cliquant sur “Accepter” (pour faire au plus simple). Dans notre cas, les cookies n’influent pas sur notre parcours et peuvent donc être acceptés, mais d’autres sites sont plus stricts à leur égard et pourront détecter vos scripts grâce à eux. Il est donc en général plutôt conseillé de refuser les cookies.
- Il faudra ensuite saisir un nom d’utilisateur, un mot de passe et cliquer sur le bouton “Connexion”. Je vous conseille de toujours utiliser un compte dédié au web scraping.
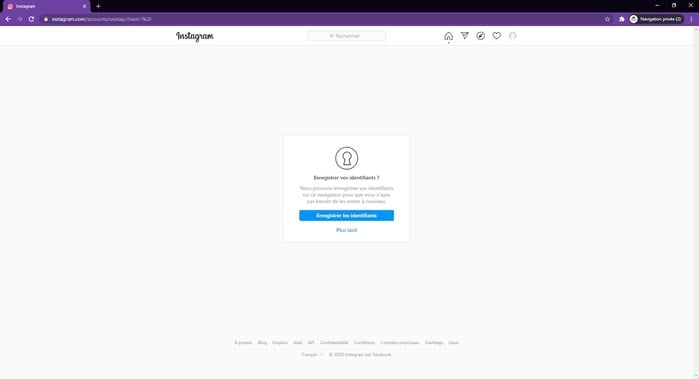
Instagram nous propose d’enregistrer nos identifiants, il faudra donc que notre robot clique sur le bouton “Plus tard”.
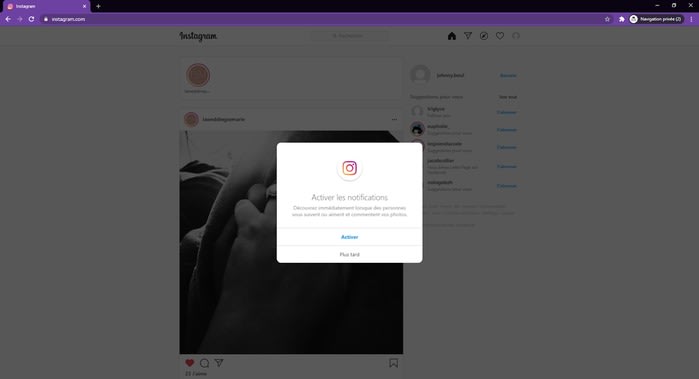
L’app apparaît enfin, et une nouvelle modale nous propose d’activer les notifications. Envoyons-la promener en cliquant sur le bouton “Plus tard”.
Nous avons enfin accès à la barre de recherche et nous avons déjà remarqué plusieurs interactions qui devront être traduites en code pour être exécutées par notre script :
- Fermer la modale cookie
- Saisir et valider le formulaire d’authentification
- Attendre la fin du chargement, puis cliquer sur “Plus tard”
- De nouveau, attendre la fin du chargement et cliquer sur “Plus tard”
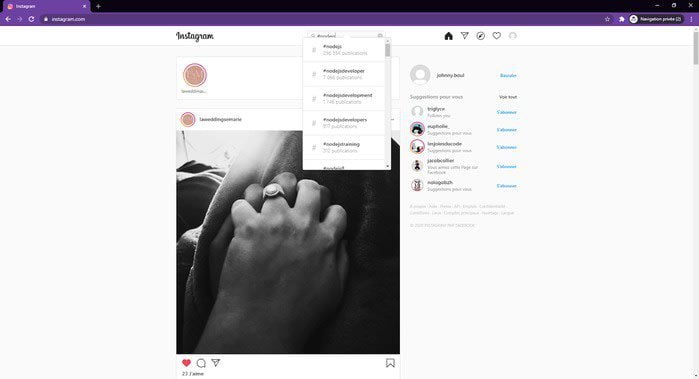
Après un court chargement, unechargementUne liste déroulante (drop-down list) s’affiche avec des suggestions. Ce type de composant d’autocomplétion (autocomplete) est courant dans les web apps modernes et est un obstacle à résoudre avec pragmatisme.
Ici, c’est la première suggestion, la plus pertinente, qui nous intéresse. En appuyant sur Tab, le focus de notre navigateur passe de la barre de recherche au bouton “Effacer la barre”. En appuyant à nouveau sur Tab, le focus passe sur la première suggestion. En appuyant ensuite sur “Entrée”, notre navigateur clique sur le lien et se rend sur la page. Bingo !
Pour ouvrir le premier résultat, notre script de web scraping devra donc réaliser les actions supplémentaires suivantes :
- Taper un hashtag dans la barre de recherche et attendre la fin du chargement
- Appuyer deux fois sur Tab
- Appuyer sur Entrée
Une nouvelle page s’est donc affichée et elle liste toutes les “meilleures publications” relatives à ce hashtag.
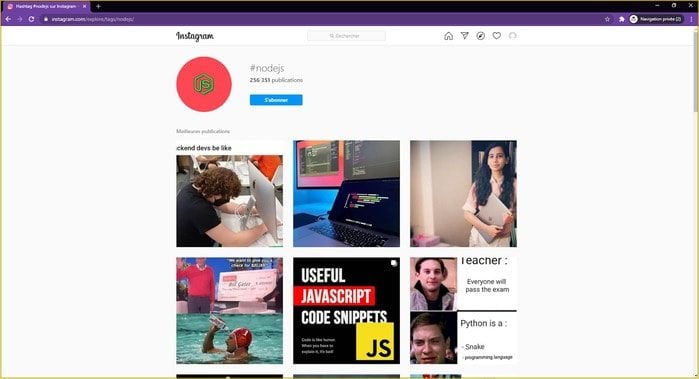
Ici, le but est de récupérer l’URL de chaque post pour la stocker et la visiter plus tard. En poussant un peu, on pourrait même implémenter une fonctionnalité de “scroll infini” vers le bas pour charger et récupérer davantage de posts.
Prochaine et avant-dernière étape : se rendre sur chaque post. Alors qu’on s’est contenté de faire du crawling jusqu’à maintenant, c’est à ce moment que le scraping à proprement parler va commencer puisque c’est là que l’on va collecter nos premières données : le texte du post et son nombre de “likes”.
C’est le bon moment pour étudier le code source de la page et remarquer qu’il est totalement obfusqué. Avec ces identifiants (les attributs “id” des éléments HTML), ces classes (les attributs “class”) et parfois même des structures entières aléatoires, il va falloir redoubler d’ingéniosité pour trouver les sélecteurs précis qui nous permettront d’obtenir la donnée à tous les coups (ou presque).
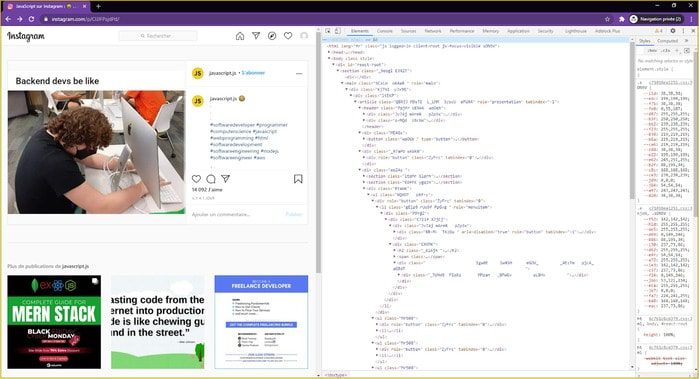
Enfin, la dernière étape importante est le scraping de la page de l’utilisateur. Il faudra donc cliquer sur son nom, attendre un nouveau chargement, et extraire son nom, nombre d’abonnés, de publications et d’abonnements ainsi que sa description.
Pour résumer, voici toutes les actions que notre bot de web scraping Instagram devra effectuer :
- Fermer la modale cookie
- Saisir et valider le formulaire d’authentification
- Attendre la fin du chargement, puis cliquer sur “Plus tard”
- De nouveau, attendre la fin du chargement et cliquer sur “Plus tard”
- Taper un hashtag dans la barre de recherche et attendre la fin du chargement
- Appuyer deux fois sur Tab
- Appuyer sur Entrée
- Attendre la fin du chargement et collecter l’URL de chaque post
- Visiter chaque URL de post et en extraire des données dont l’URL de l’utilisateur
- Visiter chaque URL d’utilisateur et en extraire des données
- Stocker les données dans un csv
Il y aura bien sûr de nombreuses optimisations possibles et nous en discuterons certaines. Voyons maintenant comment coder ce script de web scraping avec Node.js grâce à la librairie Puppeteer.
Tutoriel web scraping Instagram : le code complet
Au-delà de la librairie Puppeteer, nous aurons besoin de la librairie objects-to-csv pour insérer très facilement nos données dans un fichier csv, et de la librairie puppeteer-cluster qui va s’occuper de la parallélisation que nous aborderons un peu plus tard. Je vous laisse le soin de créer un nouveau projet Node.js et d’installer ces dépendances (voir notre tutoriel npm).
Nous allons commencer par initialiser nos différents modules avec require() :
const puppeteer = require('puppeteer')const ObjectsToCsv = require('objects-to-csv')const { Cluster } = require('puppeteer-cluster')Ensuite, nous allons définir quelques variables importantes telles que le hashtag que l’on va rechercher, les identifiants de notre compte Instagram dédié au web scraping et le chemin vers le fichier csv qui contiendra les données. Plusieurs évolutions sont possibles selon vos besoins, comme par exemple, ajouter une boucle sur plusieurs hashtags ou plusieurs utilisateurs, mais restons basiques pour commencer.
const motcle = '#nodejs'const user = 'VOTRE_NOM_D’UTILISATEUR'const mdp = 'VOTRE_MOT_DE_PASSE'const filepath = 'NOM_DU_FICHIER.csv'Le reste du code va être structuré de la même manière que dans le précédent tutoriel, c’est-à-dire imbriqué dans une IIFE (immediatly invoked function expression). Nous utiliserons également un bloc try/catch pour gérer les erreurs.
(async () => { //Le code d’initialisation du cluster sera ici try { //Le code d’initialisation du scraping sera ici } catch (err) { console.log(err); } })()Nous pouvons désormais passer au code d’initialisation du cluster.
Paralléliser les requêtes grâce à puppeteer-cluster
La notion de parallélisation est très importante en web scraping. Il s’agit d’exécuter plusieurs requêtes en même temps, de façon parallèle, afin de diminuer le temps d’exécution du script.
En local, les possibilités de parallélisations sont très utiles mais sont également limitées par les ressources disponibles sur votre machine : ne vous attendez pas à faire tourner 1000 instances de Puppeteer en parallèle sur un Windows Vista de 2006 doté d’un Pentium 4. En revanche, les possibilités sont presque infinies en déployant vos scripts dans le cloud, notamment grâce à la conteneurisation qui permet la parallélisation sur plusieurs machines différentes.
Rassurez-vous, nous pouvons déjà faire de nombreuses choses intéressantes depuis notre simple PC, et même très facilement grâce à Puppeteer-Cluster. Cette librairie permet de paramétrer rapidement la création de plusieurs instances Chromium parallèles et de leur assigner des tâches via une file d’attente. Puppeteer-cluster aide à traquer les différentes instances, tâches et erreurs, à monitorer l’utilisation des ressources, à relancer une instance en cas d’erreur…
Pour paramétrer le module, nous aurons besoin de trois éléments : un cluster, une tâche et un gestionnaire d’erreurs (optionnel).
Créer un cluster de web scraping
L’initialisation d’un cluster avec puppeteer-cluster se fait très facilement et nous allons l’insérer en premier dans la définition de notre IIFE :
const cluster = await Cluster.launch({ concurrency: Cluster.CONCURRENCY_PAGE, maxConcurrency: 4, monitor: true, timeout:30000, puppeteerOptions: { headless: false, slowMo: 250, args: [`--window-size=${1680},${970}`], }, });Remarquez que j’ai inclus plusieurs paramètres :
- concurrency : la librairie puppeteer-cluster permet de paralléliser sur plusieurs onglets de la même instance (CONCURRENCY_PAGE), sur plusieurs onglets en mode navigation privée (CONCURRENCY_CONTEXT), sur plusieurs instances Chromium différentes (CONCURRENCY_BROWSER) ou une implémentation custom. Ici, on veut s’authentifier et réaliser une seule recherche puis paralléliser sur différents onglets partageant les mêmes cookies et la même session. On choisit donc “Cluster.CONCURRENCY_PAGE”.
- maxConcurrency : il s’agit du maximum de “workers” travaillant en parallèle. Ici, j’ai indiqué 4 pour avoir au maximum 4 onglets ouverts en même temps, mais il est tout à fait possible d’augmenter ou réduire selon vos besoins, le tout en respectant l’éthique du web scraping, bien sûr.
- monitor : j’ai précisé “true” pour afficher dans la console un petit moniteur sur l’état du script et des ressources (quels workers sont en train de travailler, combien de tâches ont été réalisées, combien d’erreurs, consommation du CPU…)
- timeout : il s’agit d’un timer appliqué à toutes les tâches et à la fin duquel la tâche est terminée et déclarée erreur pour laisser le worker passer à la tâche suivante. J’ai laissé la valeur par défaut de 30 secondes. Il est également possible d’indiquer une retryLimit (par défaut : 0) pour réessayer automatiquement une tâche déclarée erreur et un retryDelay, délai à appliquer entre l’échec d’une tâche et un nouvel essai.
L’avantage de cette librairie, c’est qu’elle s’occupe du lancement des instances nécessaires toute seule. Nous n’avons donc pas à initialiser puppeteer nous-mêmes comme dans le dernier tutoriel, et nous pouvons passer des options d’initialisation pendant la création du Cluster. J’ai par exemple appliqué les paramètres suivants :
- headless : (par défaut : true). J’ai désactivé ce paramètre pour que nous puissions visualiser chaque action réalisée par le bot ainsi que la création des différents onglets, mais vous pouvez désactiver l’option pour améliorer le temps d’exécution du script. Veuillez noter que lancer vos scripts de web scraping en mode headless les rend plus facilement détectables
- slowMo : ce paramètre permet de ralentir le fonctionnement entier du script pour rendre chaque action plus visible et également réduire les probabilités de détection du script de web scraping par les protections d’Instagram. Je vous conseille une valeur entre 100 et 500.
- args permet enfin de passer des arguments supplémentaires à la création de l’instance Chrome. On pourrait ici par exemple randomiser les différentes tailles de viewport.
Notre cluster est fin prêt et nous pouvons maintenant procéder à la création d’un petit gestionnaire d’erreurs simpliste.
Gestionnaire d’erreurs web scraping
Lorsque notre cluster va générer une erreur, par exemple suite à l’échéance du timeout ou à un bug dans votre code, il va le faire via un événement “taskerror”.
Nous allons donc créer un gestionnaire écoutant cet évènement (event handler) qui va afficher un message (en fonction d’un éventuel réessai de la tâche qui a échoué) dans la console ainsi que l’erreur en question :
cluster.on('taskerror', (err, data, willRetry) => { if (willRetry) console.warn(`Erreur de scraping, réessai prévu : `); else console.error(`Erreur de scraping :`); console.log(err); });Gardons ce gestionnaire simple et passons au code de notre tâche de scraping.
Création des tâches de scraping
Après avoir créé notre cluster et géré les erreurs qu’il pourrait générer, nous allons maintenant écrire une tâche à lui assigner. Puppeteer-cluster ne permet pas (à ma connaissance) de créer plusieurs tâches différentes, nous allons donc encapsuler plusieurs suites d’actions dans une seule et unique tâche.
Suite à notre travail préliminaire, nous savons que nous avons trois grandes suites d’action ou trois étapes différentes à réaliser :
- Se connecter, chercher un hashtag et stocker chaque URL de post (suite d’actions séquentielle, donc à effectuer l’une après l’autre)
- Se rendre sur chaque URL de post, collecter certaines données dont les URL d’utilisateurs (à effectuer de manière asynchrone, c’est-à-dire de façon parallélisée sur plusieurs onglets différents)
- Se rendre sur chaque URL d’utilisateur, collecter le reste des données là aussi de manière asynchrone.
Ainsi, dès que notre script a effectué la recherche et collecté les URL de chaque post pour cette recherche (première tâche), nous allons ajouter chaque URL à une file d’attente et les ouvrir à la suite sur 4 onglets simultanés pour collecter les données voulues. Dès qu’une tâche est terminée sur un onglet, celui-ci sera rendu disponible pour en recevoir une nouvelle jusqu’à l’écoulement de toutes les tâches.
Pour plus de lisibilité, j’ai choisi de séparer ces trois étapes différentes dans trois fonctions différentes :
- getPosts(page) : se rend simplement sur le premier onglet vide créé par le Cluster, effectue la recherche et collecte les URL des posts
- getProfiles(page,url,cluster) : ensuite, nous utiliserons cette fonction sur chaque url collectée par getPosts() pour collecter les données de post et les url d’utilisateurs. Nous avons besoin du cluster car nous allons lui ajouter des tâches dans sa file d’attente.
- getData(page,url,body,likes) : enfin, nous exécutons cette fonction sur chaque url collectée par getProfiles() pour récupérer le reste des données. Nous lui passons également body (le texte du post) et likes (le nombre de likes du post) récupéré pour cette url par getProfiles() pour pouvoir insérer le tout dans le fichier csv.
Pour écrire notre tâche, nous allons simplement invoquer l’une de ces trois fonctions en fonction d’un paramètre passé à la tâche :
- si j’assigne cette tâche au cluster sans paramètre, j’invoquerai getPosts() – car cette fonction est la première à exécuter, elle n’a besoin d’aucun paramètre si ce n’est la page du cluster.
- si j’assigne cette tâche au cluster avec le paramètre getProfiles, j’invoquerai la fonction getProfiles() pour effectuer le scraping sur les URL des posts.
- si j’assigne cette tâche au cluster avec le pramètre getData, j’invoquerai la fonction getData() pour effectuer le scraping sur les URL des utilisateurs.
Ce qui donne, en code :
await cluster.task(async ({ page, data: elem }) => { if (typeof elem.getProfiles !== 'undefined') { return await getProfiles(page,elem.getProfiles,cluster) } else if (typeof elem.getData !== 'undefined') { return await getData(page,elem.getData,elem.body,elem.likes) } else{ return await getPosts(page) } });Avant de passer au code de web scraping à proprement parler, il n’y a plus qu’à rajouter quelques lignes pour assigner ces tâches au cluster dans le bloc try/catch, après l’initialisation du cluster, du gestionnaire d’erreurs et de la tâche :
try { const results = await cluster.execute('https://www.instagram.com/'); //console.log(results); results.forEach(result => cluster.queue({getProfiles:result})); } catch (err) { console.log(err); }Comme vous pouvez le constater, je commence par invoquer la méthode execute() sur le cluster. Cela signifie que la tâche est immédiatement exécutée, sans lui passer de paramètre, si ce n’est l’url sur laquelle se rendre. Surtout, cela signifie que le script attend la fin de la tâche pour continuer. Ce sera donc la fonction getPosts(), la première de nos trois grandes étapes, qui sera invoquée, et elle sera ainsi exécutée de façon séquentielle.
Ses résultats, la liste des URL des posts, sont stockés dans la variable “results”. Vous pouvez décommenter le commentaire pour constater les résultats dans la console. On vient ensuite itérer sur les résultats via une boucle forEach() dans laquelle on invoque la méthode cluster.queue(). À l’inverse d’execute(), queue() assigne la tâche à une file d’attente qui va nourrir le pool d’instances disponibles (ici, nos 4 onglets parallèles). On lui passe chaque résultat renvoyé par getPosts() dans le paramètre getProfiles pour invoquer la fonction getProfiles() sur chaque url, notre deuxième étape.
C’est à l’intérieur de getProfiles() que l’on ajoutera les derniers évènements à la file d’attente de notre cluster de web scraping pour invoquer notre dernière étape avec getData().
Pour l’instant, notre code complet ressemble à ceci :
onst puppeteer = require('puppeteer')const ObjectsToCsv = require('objects-to-csv')const { Cluster } = require('puppeteer-cluster')const motcle = '#nodejs'const user = 'VOTRE_NOM_D’UTILISATEUR'const mdp = 'VOTRE_MOT_DE_PASSE'const filepath = 'NOM_DU_FICHIER.csv' (async () => { const cluster = await Cluster.launch({ concurrency: Cluster.CONCURRENCY_PAGE, maxConcurrency: 4, monitor: true, timeout:30000, puppeteerOptions: { headless: false, slowMo: 250, args: [`--window-size=${1680},${970}`], }, }); cluster.on('taskerror', (err, data, willRetry) => { if (willRetry) console.warn(`Erreur de scraping, réessai prévu : `) else console.error(`Erreur de scraping :`) console.log(err) }); await cluster.task(async ({ page, data: elem }) => { if (typeof elem.getProfiles !== 'undefined') { return await getProfiles(page,elem.getProfiles,cluster) } else if (typeof elem.getData !== 'undefined') { return await getData(page,elem.getData,elem.body,elem.likes) } else{ return await getPosts(page) } }); try { const results = await cluster.execute('https://www.instagram.com/'); //console.log(results); results.forEach(result => cluster.queue({getProfiles:result})); } catch (err) { console.log(err); } })()Il ne nous reste plus qu’à écrire nos trois fonctions de web scraping getPosts(), getProfiles() et getData().
Web scraping : extraction de données avec puppeteer
On en a fini avec la structure, c’est maintenant le moment de mettre les mains dans le cambouis. Première étape sur notre route : la fonction getPosts() qui va nous permettre de nous connecter, effectuer une recherche sur Instagram et collecter les URL de tous les posts issus de la recherche.
Pour rappel, voici les différentes actions prévues :
- Fermer la modale cookie
- Saisir et valider le formulaire d’authentification
- Attendre la fin du chargement, puis cliquer sur “Plus tard”
- De nouveau, cliquer sur “Plus tard”
- Taper un hashtag dans la barre de recherche et attendre la fin du chargement
- Appuyer deux fois sur Tab
- Appuyer sur Entrée
- Attendre la fin du chargement et collecter l’URL de chaque post
- Visiter chaque URL de post et en extraire des données dont l’URL de l’utilisateur
- Visiter chaque URL d’utilisateur et en extraire des données
- Stocker les données dans un csv
Authentification sur la web app
Définissons notre fonction getPosts() comme suit :
async function getPosts(page){}(Action 1) Suite à notre travail préliminaire, on sait que notre script de web scraping doit se rendre sur la page d’accueil et cliquer sur le bouton “Accepter” de la modale cookie :
await page.goto('https://www.instagram.com/') console.log('-> RECHERCHE bouton cookie') const [button2] = await page.$x("//button[contains(., 'Accepter')]"); if (button2) { console.log('-> TROUVE bouton cookie') await button2.click() } else { console.log('-> NON TROUVE bouton cookie ') }Notez que j’utilise beaucoup de console.log() pour montrer dans la console où se situe le script. Concernant le bouton cookie, j’ai utilisé un sélecteur xPath (voir précédent tutoriel) avec page.$x(), ce qui permet d’utiliser l’expression contains() pour trouver un élément (ici un bouton) par le contenu de son texte. Si le bouton est trouvé, le script clique dessus.
(Action 2) On remplit ensuite notre formulaire de connexion à Instagram :
await page.waitForSelector('input[name="username"]') await page.type('input[name="username"]', user) await page.type('input[name="password"]', mdp)On valide le formulaire et on attend la fin du chargement avec waitforNavigation():
await Promise.all([ await page.click('button[type="submit"]'), page.waitForNavigation({ waitUntil: 'networkidle0', }), ]);(Action 3) On cherche ensuite le bouton “plus tard” et on clique dessus, puis on attend la fin du chargement :
console.log('-> RECHERCHE bouton plus tard 1') const [button1] = await page.$x("//button[contains(., 'Plus tard')]"); if (button1) { console.log('-> TROUVE bouton plus tard 1') await Promise.all([ await button1.click(), page.waitForNavigation({ waitUntil: 'networkidle0', }), ]); } else { console.log('-> NON TROUVE bouton plus tard 1') }(Action 4) Même principe avec le deuxième bouton “plus tard”, mais celui-ci ne provoque pas de chargement, donc pas besoin d’attendre la fin du chargement :
console.log('-> RECHERCHE bouton plus tard 2') const [button3] = await page.$x("//button[contains(., 'Plus tard')]"); if (button3) { console.log('-> TROUVE bouton plus tard 2') await button3.click() } else { console.log('-> NON TROUVE bouton plus tard 2') }(Action 5) On laisse un petit délai pour ralentir le fonctionnement du script et on tape le mot-clé dans la barre de recherche, puis on attend l’apparition de l’icône de chargement de l’autocomplete :
console.log('-> Délai de sécurité') await page.waitForTimeout(2000) console.log('-> SEARCH - Typing search') await page.type('input[placeholder="Rechercher"]', motcle) await page.waitForSelector('div.coreSpriteSearchClear')(Actions 6 et 7) On tape deux fois sur Tab, puis sur Entrée et on attend la fin du chargement de la page de la première suggestion de l’autocomplete :
await page.keyboard.press('Tab') await page.keyboard.press('Tab') console.log('-> APPUI ENTREE - RECHERCHE') await Promise.all([ await page.keyboard.press('Enter'), page.waitForNavigation({ waitUntil: 'networkidle0', }), ]); console.log('-> RECHERCHE - FIN CHARGEMENT')(Action 8) Enfin, on laisse un nouveau délai, puis on stocke dans la constante hrefs toutes les URL (les attributs href) des liens menant vers des posts avant de retourner hrefs :
await page.waitForTimeout(2000) const hrefs = await page.evaluate( () => Array.from( document.querySelectorAll('main[role="main"] > article > div:nth-of-type(2) > div > div > div a'), a => a.getAttribute('href') ) ); return hrefs;Ça y est, notre première fonction getPosts()est en place et retourne les URL de chaque post issus de notre recherche. Il s’agit de la plus grosse fonction, les autres sont plus légères.
Passons maintenant à notre fonction getProfiles() qui, pour chacune de ces URL, va collecter certaines informations et passer le relais à getData() par la suite.
Extraction de posts Instagram grâce au web scraping avec Puppeteer
Définissons notre fonction getProfiles() comme suit :
async function getProfiles(page,url,cluster){}Pour rappel, le paramètre url est une URL collectée par la fonction getPosts() et passée à la tâche assignée au cluster dans le bloc try/catch. Le paramètre cluster est le cluster, nous en avons besoin pour lui assigner des tâches. Enfin, le paramètre page est tout simplement l’onglet disponible dans lequel la fonction est invoquée.
(Action 9) Rendons-nous sur l’url du post pour y effectuer le scraping :
await page.goto('https://www.instagram.com'+url)Extrayons l’url de l’utilisateur ayant posté ce post et stockons-la dans une constante “link”Notez l’utilisation d’un sélecteur CSS spécifique : on cherche à récupérer un élément a(un lien) bien particulier, dont l’attribut href ne mène pas à une page dont l’url contient “explore”. On utilise ce sélecteur pour être sûr de collecter une URL de page d’utilisateur et non de lieu.
Extrayons maintenant le texte (le body) du post :
const selector_body = await page.$x("//h2/../span"); const text = await page.evaluate(e => e.textContent, selector_body[0]);Constatez qu’on définit d’abord un élément grâce à un sélecteur (ici xPath), et qu’on le stocke ensuite dans une constante (ici “text”).
Même principe pour le nombre de likes du post :
const selector_likes = await page.$x("//button[contains(., 'aime')]//span"); const likes = await page.evaluate(e => e.textContent, selector_likes[0]);On ajoute maintenant une nouvelle tâche à la file d’attente du cluster. Cette fois, on lui passe l’url de l’utilisateur qui vient d’être collectée via le paramètre getData (pour invoquer la fonction getData() dans la tâche), et on lui passe également le texte du post dans le paramètre body et le nombre de likes dans le paramètre likes.
cluster.queue({getData:link,body:text,likes:likes})Enfin, on retourne le lien pour signifier que la tâche est terminée :
return link;C’est tout pour notre fonction getProfiles() qui effectue le scraping des url utilisateurs, ainsi que du nombre de likes et du texte des posts. Il faut désormais terminer le dernier bloc de notre script : la fonction getData() qui extrait les données utilisateurs des pages utilisateurs.
Extraction de données utilisateur Instagram (abonnés, abonnements, publications)
On suit le même principe, commençons par définir notre fonction getData() comme suit :
async function getData(page,url,body,likes){}Créons ensuite un tableau vide pour accueillir nos résultats finaux :
let r = [](Action 10) En suivant le même principe que dans la fonction précédente, on définit des sélecteurs et on extrait les données du code HTML de la page pour les stocker dans des variables:
await page.goto('https://www.instagram.com'+url) await page.waitForSelector('h1') await page.waitForTimeout(500) let selector_nom = await page.$('section > div:first-of-type > h1,h2') let nom = await page.evaluate(el => el.innerText, selector_nom) let selector_bio = await page.$('main > div > header > section > div:nth-of-type(2) > span') let bio = await page.evaluate(el => el.innerText, selector_bio) let selector_stats = await page.$$('main > div > header > section > ul > li span span, main > div > header > section > ul > li a span') let stats_publi = await page.evaluate(el => el.innerText, selector_stats[0]) let stats_abonnes = await page.evaluate(el => el.innerText, selector_stats[1]) let stats_abonnements = await page.evaluate(el => el.innerText, selector_stats[2])Notez l’utilisation de plusieurs sélecteurs complexes avec des conditions “OU” (virgule à l’intérieur d’un sélecteur CSS, par exemple “h1,h2”). Si j’en suis arrivé à utiliser ce type de sélecteurs, c’est parce que Instagram randomise une certaine partie de son template et place parfois certaines informations dans, par exemple, un h1, et d’autres fois dans un h2.
Ensuite, on pousse dans notre tableau r ces informations sous la forme d’objet :
r.push({"post_body" : body, "post_likes" : likes, "user_name" : nom, "user_bio" : bio, "user_publications" : stats_publi, "user_abonnes" : stats_abonnes, "user_abonnements" : stats_abonnements})//console.log(r)On peut éventuellement constater l’objet ainsi créé en décommentant la ligne console.log(r).
(Action 11) Enfin, c’est le moment d’utiliser notre librairie objects-to-csv pour ajouter les résultats au fur et à mesure dans un fichier .csv :
let csv = new ObjectsToCsv(r)await csv.toDisk(filepath, { append: true })returnNotez l’utilisation de append : true pour ajouter les données aux données existantes et non les écraser. Vous pouvez également constater que l’on signifie la fin de la tâche avec return.
Réunies, nos trois fonctions getPosts(), getProfiles() et getData()ressemblent à ceci :
async function getPosts(page){ await page.goto('https://www.instagram.com/') console.log('-> RECHERCHE bouton cookie') const [button2] = await page.$x("//button[contains(., 'Accepter')]"); if (button2) { console.log('-> TROUVE bouton cookie') await button2.click() } else console.log('-> NON TROUVE bouton cookie ') await page.waitForSelector('input[name="username"]') await page.type('input[name="username"]', user) await page.type('input[name="password"]', mdp) await Promise.all([ await page.click('button[type="submit"]'), page.waitForNavigation({ waitUntil: 'networkidle0', }), ]); console.log('-> RECHERCHE bouton plus tard 1') const [button1] = await page.$x("//button[contains(., 'Plus tard')]"); if (button1) { console.log('-> TROUVE bouton plus tard 1') await Promise.all([ await button1.click(), page.waitForNavigation({ waitUntil: 'networkidle0', }), ]); } else console.log('NON TROUVE bouton plus tard 1') console.log('-> RECHERCHE bouton plus tard 2') const [button3] = await page.$x("//button[contains(., 'Plus tard')]"); if (button3) { console.log('-> TROUVE bouton plus tard 2') await button3.click() } else console.log('-> NON TROUVE bouton plus tard 2') console.log('-> Délai de sécurité') await page.waitForTimeout(2000) console.log('-> SEARCH - Typing search') await page.type('input[placeholder="Rechercher"]', motcle) await page.waitForSelector('div.coreSpriteSearchClear') await page.keyboard.press('Tab') await page.keyboard.press('Tab') console.log('-> APPUI ENTREE - RECHERCHE') await Promise.all([ await page.keyboard.press('Enter'), page.waitForNavigation({ waitUntil: 'networkidle0', }), ]); console.log('-> RECHERCHE - FIN CHARGEMENT') await page.waitForTimeout(2000) const hrefs = await page.evaluate( () => Array.from( document.querySelectorAll('main[role="main"] > article > div:nth-of-type(2) > div > div > div a'), a => a.getAttribute('href') ) ); return hrefs;}async function getProfiles(page,url,cluster){ await page.goto('https://www.instagram.com'+url) const link = await page.$eval("article header div a:not([href*='explore'])", anchor => anchor.getAttribute('href')); const selector_body = await page.$x("//h2/../span"); const text = await page.evaluate(e => e.textContent, selector_body[0]); const selector_likes = await page.$x("//button[contains(., 'aime')]//span"); const likes = await page.evaluate(e => e.textContent, selector_likes[0]); cluster.queue({getData:link,body:text,likes:likes}) return link;}async function getData(page,url,body,likes){ let r = [] await page.goto('https://www.instagram.com'+url) await page.waitForSelector('h1') await page.waitForTimeout(500) let selector_nom = await page.$('section > div:first-of-type > h1,h2') let nom = await page.evaluate(el => el.innerText, selector_nom) let selector_bio = await page.$('main > div > header > section > div:nth-of-type(2) > span') let bio = await page.evaluate(el => el.innerText, selector_bio) let selector_stats = await page.$$('main > div > header > section > ul > li span span, main > div > header > section > ul > li a span') let stats_publi = await page.evaluate(el => el.innerText, selector_stats[0]) let stats_abonnes = await page.evaluate(el => el.innerText, selector_stats[1]) let stats_abonnements = await page.evaluate(el => el.innerText, selector_stats[2]) r.push({"post_body" : body, "post_likes" : likes, "user_name" : nom, "user_bio" : bio, "user_publications" : stats_publi, "user_abonnes" : stats_abonnes, "user_abonnements" : stats_abonnements}) //console.log(r) let csv = new ObjectsToCsv(r) await csv.toDisk(filepath, { append: true }) return}Il est temps de tester notre script ! Voilà les résultats que j’obtiens :

À l’heure où j’écris ces lignes, ce code est entièrement fonctionnel. Mais les web apps telles qu’Instagram changent très régulièrement de template et vous devrez passer un certain temps à maintenir vos scripts de web scraping pour pouvoir les utiliser régulièrement.
Parmi les évolutions possibles : réaliser d’autres tâches telles qu’aimer une publication ou s’abonner à une page, paralléliser sur plusieurs comptes et plusieurs instances de Chromium différentes, introduire un “scroll infini” vers le bas pour récupérer davantage de posts etc…



